Evaluation(评估)
为什么应该评估模型?
认识一下 Alex——一家中型公司的机器学习工程师。Alex 知道市面上有众多 AI 模型——GPT、LLaMA 等等——但哪个最适合手头的工作?它们在纸面上听起来都很出色,但 Alex 不能仅凭公开的排行榜来决策。这些模型在不同场景下的表现各异,而且某些模型可能已经在评估数据集上进行了训练(不诚实!)。此外,这些模型的写作风格有时……感觉不对劲。
这就是 Open WebUI 的用武之地。它为 Alex 及其团队提供了一种简单的方式,根据实际需求来评估模型。无需复杂的数学计算,无需繁重的操作。只需在与模型交互时点赞或踩。
简而言之
- 为什么评估很重要:模型众多,但并非所有模型都适合您的特定需求。公开的通用排行榜并不总是可信的。
- 如何解决这个问题:Open WebUI 提供内置的评估系统。使用点赞/踩对模型响应评分。
- 幕后发生了什么:评分会调整您的个性化排行榜,已评分对话的快照将用于未来的模型微调!
- 评估选项:
- 竞技场模式:随机为您选择模型进行比较。
- 普通交互:像平常一��样聊天并对响应评分。
为什么公开评估还不够?
- 公开的排行榜并不针对您的特定使用场景。
- 某些模型在评估数据集上进行了训练,影响了结果的公正性。
- 一个模型整体表现可能很好,但其沟通风格或响应内容与您想要的"感觉"不符。
解决方案:使用 Open WebUI 进行个性化评估
Open WebUI 有一个内置的评估功能,让您和您的团队在与模型交互的过程中,发现最适合您特定需求的模型。
怎么运作的?很简单!
- 在对话过程中,如果您喜欢某个响应就点赞,不喜欢就点踩。如果消息有兄弟消息(例如重新生成的响应或并排模型比较的一部分),您就在为您的个人排行榜做贡献。
- 排行榜可在管理面板中轻松访问,帮助您跟踪哪些模型根据团队的评价表现最佳。
有一个很酷的功能?每当您对响应评分时,系统会捕获该对话的快照,这些快照后续将用于精炼模型,甚至为未来的模型训练提供数据。(请注意,此功能仍在开发中!)
评估 AI 模型的两种方式
Open WebUI 提供两种直接的 AI 模型评估方法。
1. 竞技场模式
竞技场模式从可用模型池中随机选择,确保评估公平无偏。这有助于消除手动比较中的一个潜在缺陷:生态有效性——确保您不会有意或无意地偏向某个模型。
使用方法:
- 从竞技场模式选择器中选择一个模型。
- 像平常一样使用,但现在您处于"竞技场模式"。
要让您的反馈影响排行榜,您需要所谓的兄弟消息。什么是兄弟消息?兄弟消息就是由同一查询生成的任何替代响应(想想消息重新生成或多个模型并排生成响应)。这样,您就在正面对决地比较响应。
- 评分技巧:当您为一个响应点赞时,另一个会自动获得踩。因此要谨慎,只为您真正认为最好的消息点赞!
- 对响应评分后,您可以查看排行榜,了解各模型的排名情况。
下面是竞技场模式界面的预览:
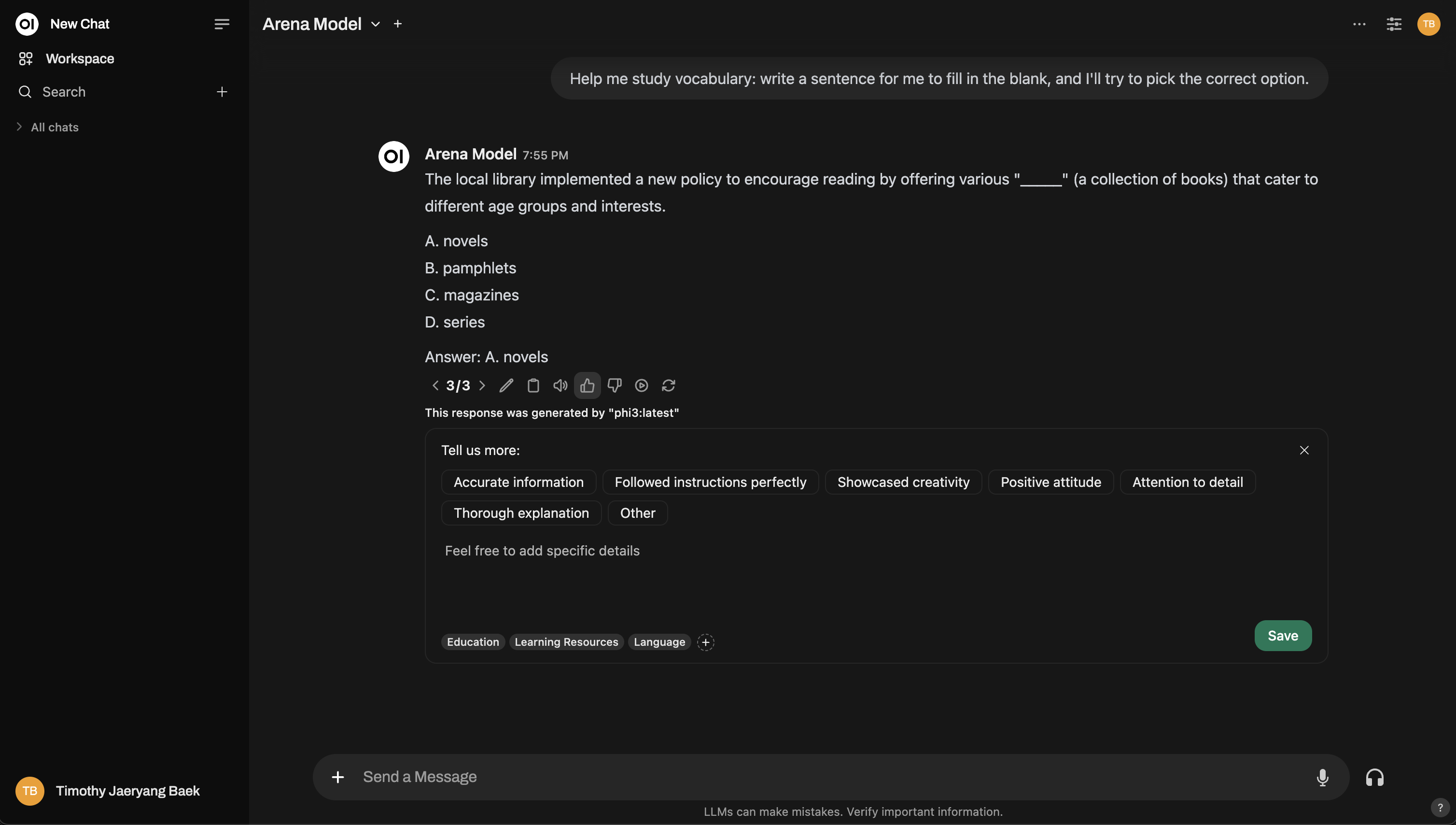
想要更深入的体验?您甚至可以复制 Chatbot Arena 风格的设置!
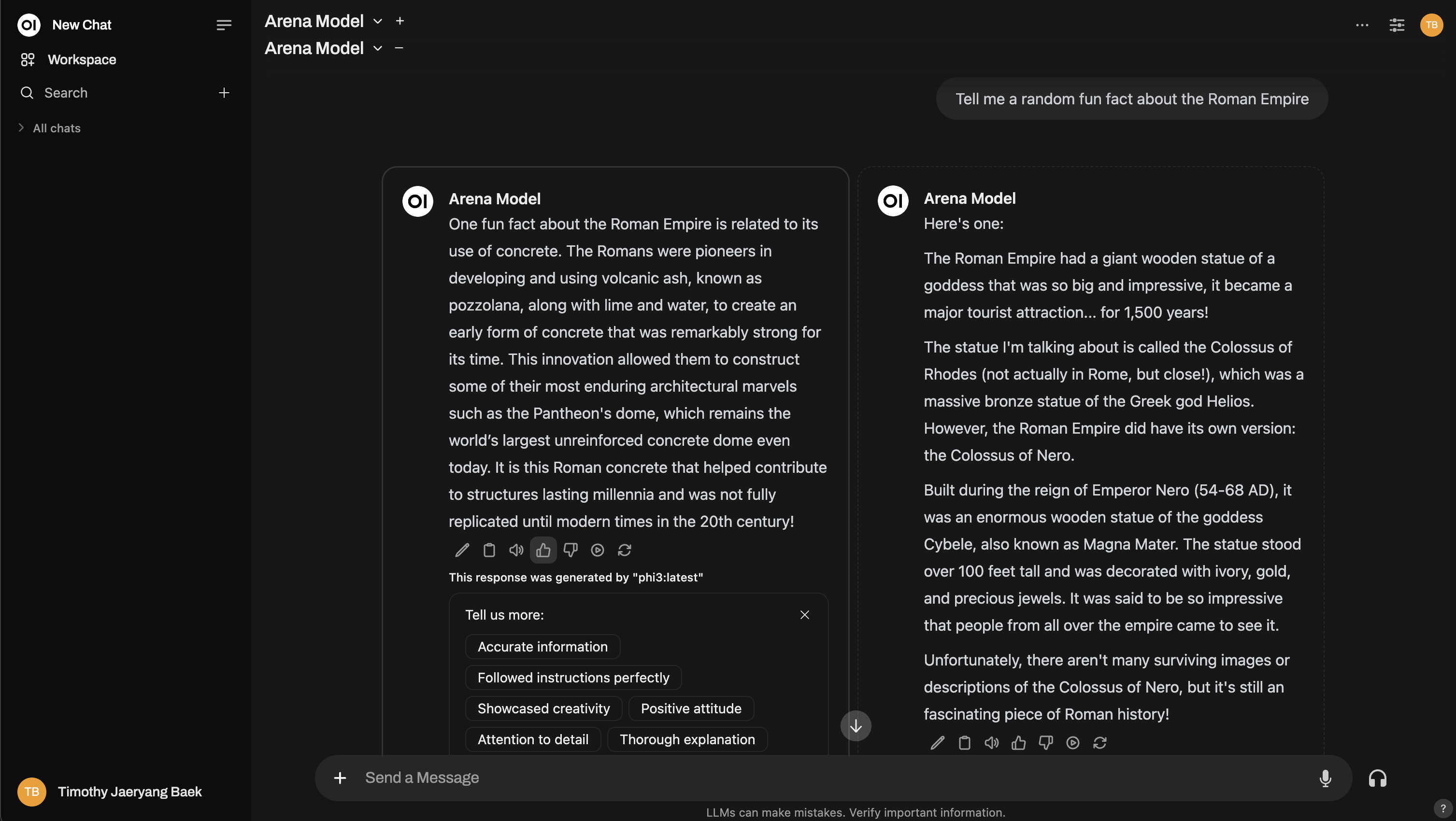
2. 普通交互
如果您不想切换到"竞技场模式",完全没问题。您可以像平常一样使用 Open WebUI,并在日常操作中对 AI 模型响应评分。随时对模型响应点赞/踩即可。但是,如果您希望您的反馈用于排行榜排名,您需要切换模型并与不同的模型交互。这确保存在兄弟响应可供比较——只有两个不同模型之间的比较才会影响排名。
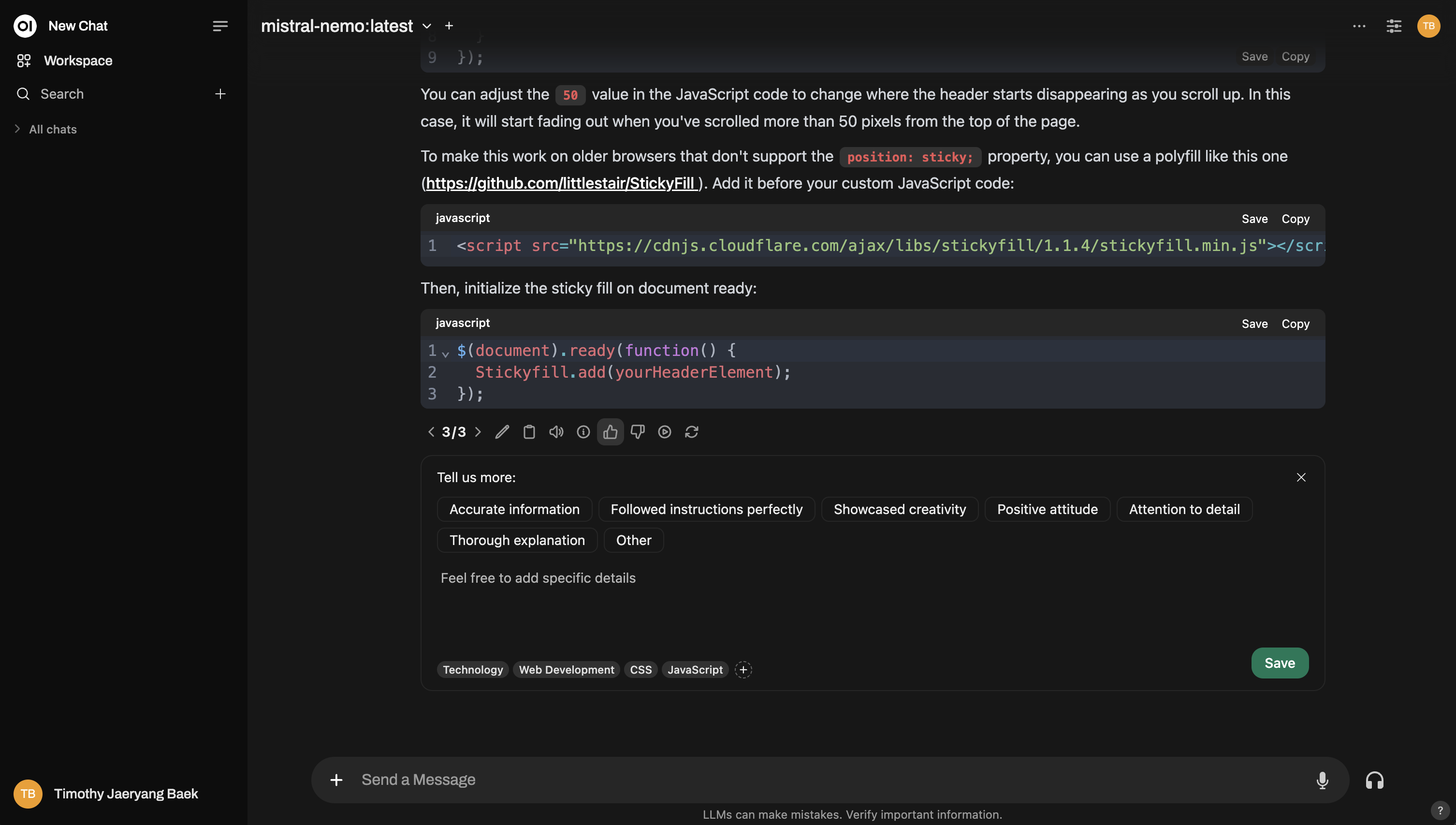
例如,这是在普通交互中如何评分:
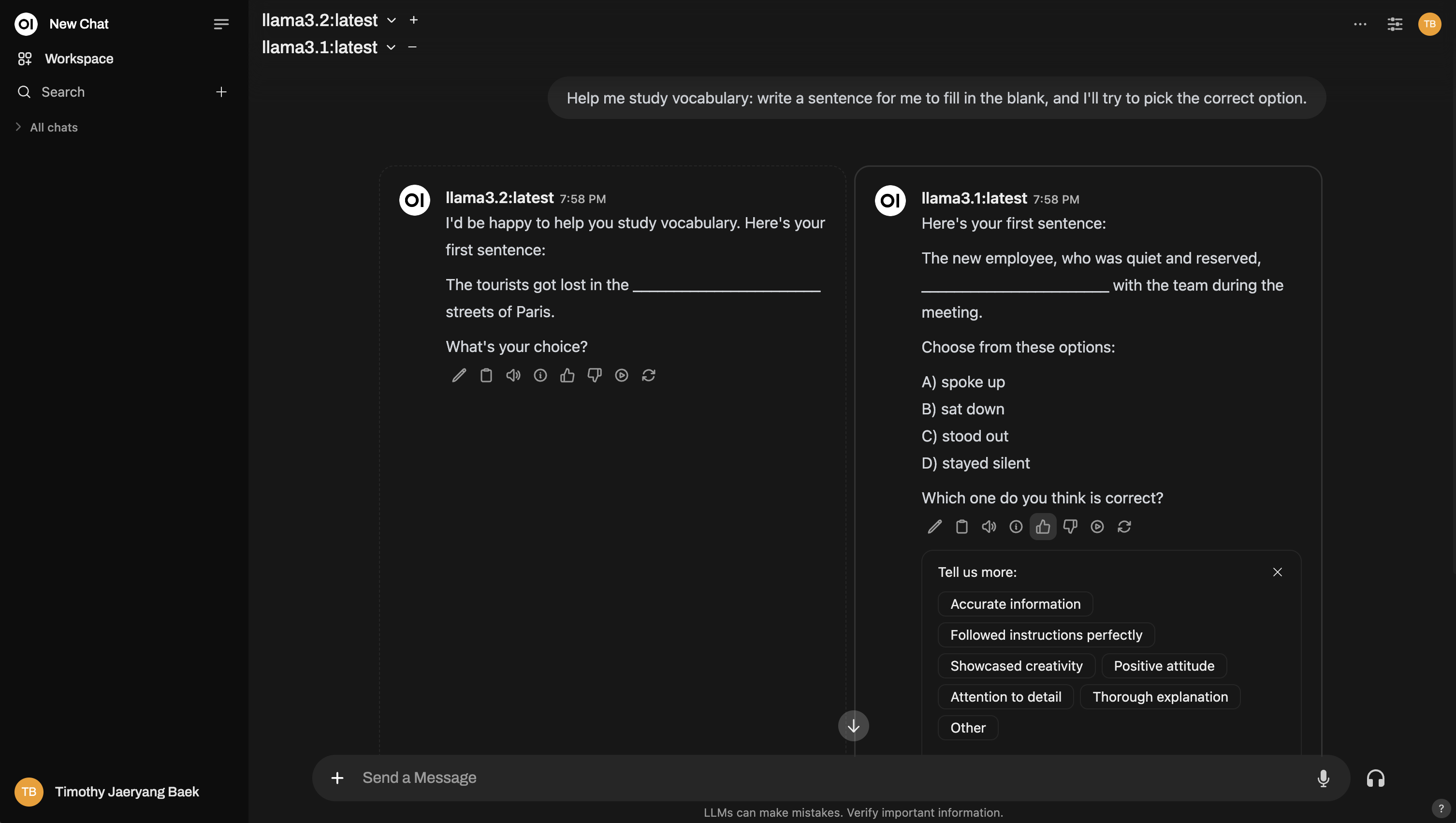
以及如何设置多模型比较,类似于竞技场:
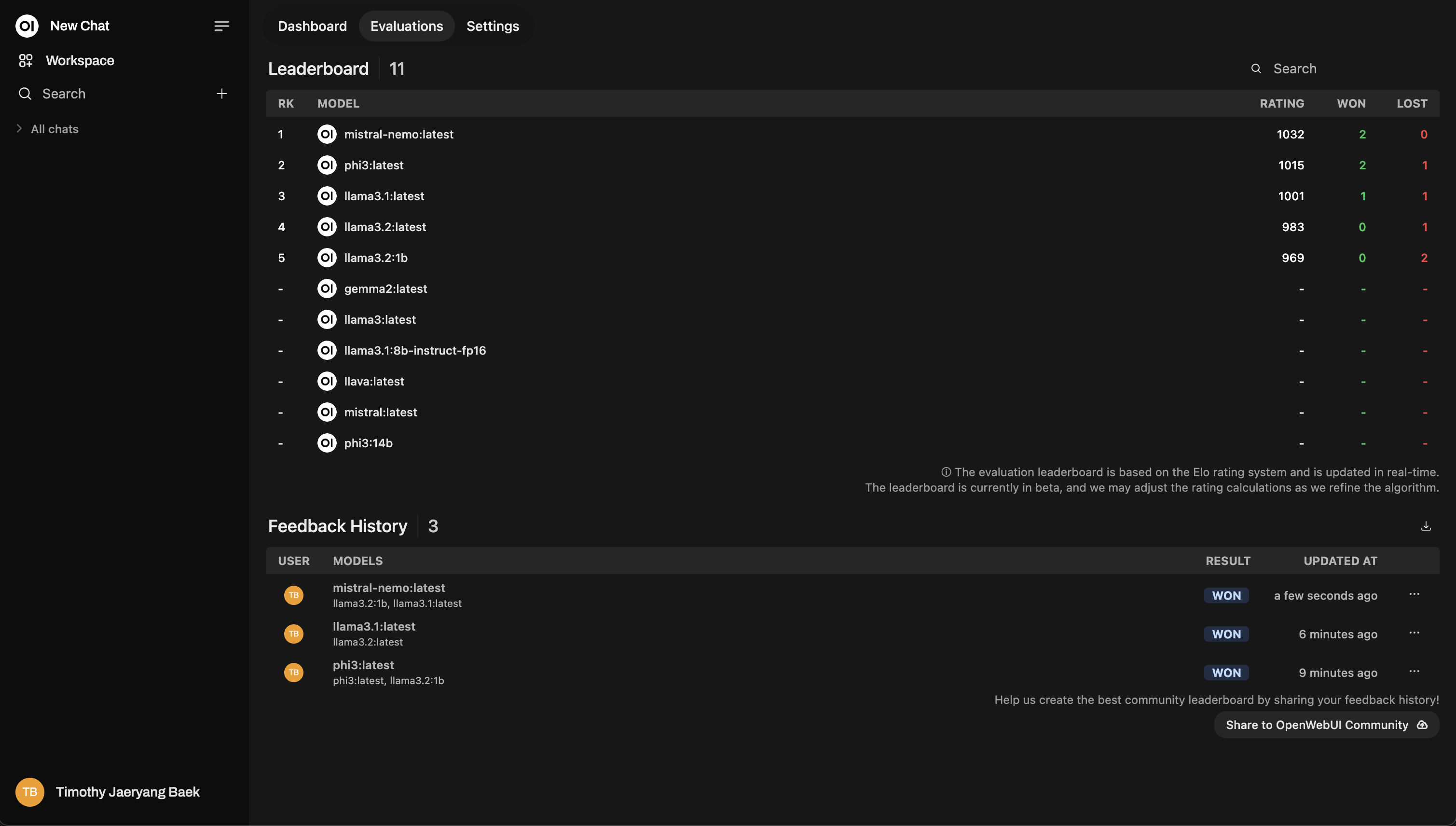
排行榜
评分后,查看管理面板下的排行榜。这里您将直观地看到模型的表现,使用 Elo 评分系统(类似国际象棋评级!)进行排名。您将真实地看到哪些模型在评估中真正脱颖而出。
这是一个排行榜布局示例:
模型活动跟踪
除了总体 Elo 评分外,您现在还可以通过模型活动图表查看模型的历史表现。此功能提供了模型评估随时间演变的时间顺序视图。
- 分叉图表:图表按日或按周显示胜利(正)和失败(负),清楚地展示模型随时间的可靠性。
- 时间范围:您可以在不同时间范围之间切换:30 天、1 年或全部时间。
- 周聚合:对于较长的时间范围(1 年和全部时间),数据会自动按周聚合,以提供更平滑、更易读的趋势。
要查看活动图表,请点击排行榜中的某个模型,打开其详细评估模态框。
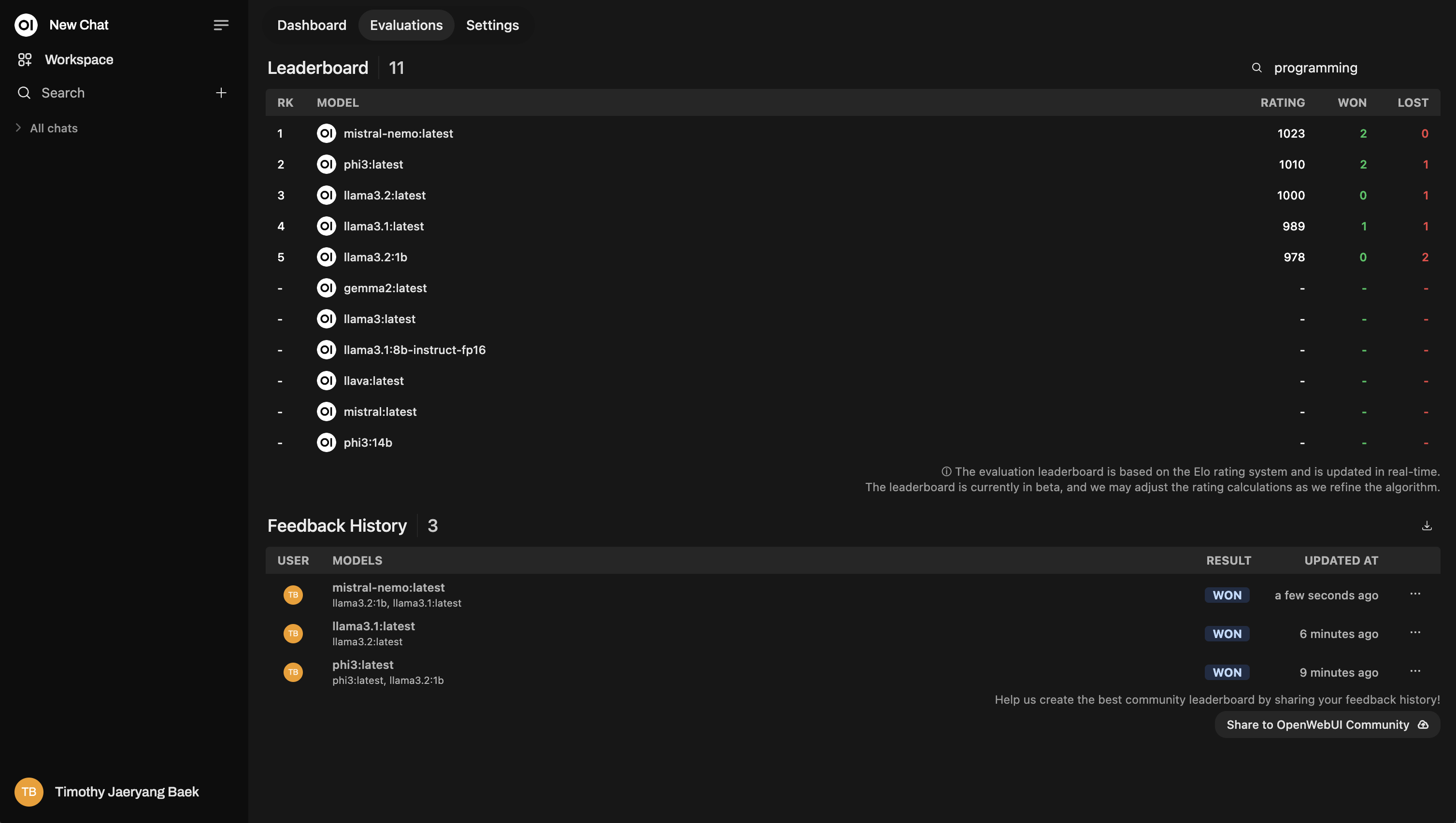
对对话评分时,您可以按主题打标签以获得更细粒度的洞察。如果您在客户服务、创意写作、技术支持等不同领域工作,这尤其有用。
自动标签
Open WebUI 会尝试根据对话主题自动为对话打标签。但是,根据您使用的模型,自动标签功能有时可能失败或误解对话。发生这种情况时,最好手动为对话打标签以确保反馈准确。
- 如何手动打标签:对响应评分时,您可以根据对话的上下文添加自己的标签。
不要跳过这一步!打标签非常强大,因为它让您能够根据特定主题重新排名模型。例如,您可能想查看哪个模型在回答技术支持问题方面表现最好,而不是一般客户咨询。
以下是重新排名的示例:
附注:用于模型微调的对话快照
每当您对模型响应评分时,Open WebUI 都会捕获该对话的快照。这些快照最终可用于微调您自己的模型——因此您的评估会推动 AI 的持续改进。
(请继续关注此功能的更多更新,它正在积极开发中!)
总结
简而言之,Open WebUI 的评估系统有两个明确目标:
- 帮助您轻松比较模型。
- 最终找到与您个人需求最契合的模型。
该系统的核心是让 AI 模型评估对每个用户来说都简单、透明且可定制。无论是通过竞技场模式还是普通对话交互,您掌控着决定哪个 AI 模型最适合您特定使用场景的权力!
默认情况下,所有评估数据都保留在�您的实例上,除非您特别选择加入社区共享,否则不会分享任何数据。